
ArXiv
Preprint
Source Code
Github

Neuron Catalog
Demo
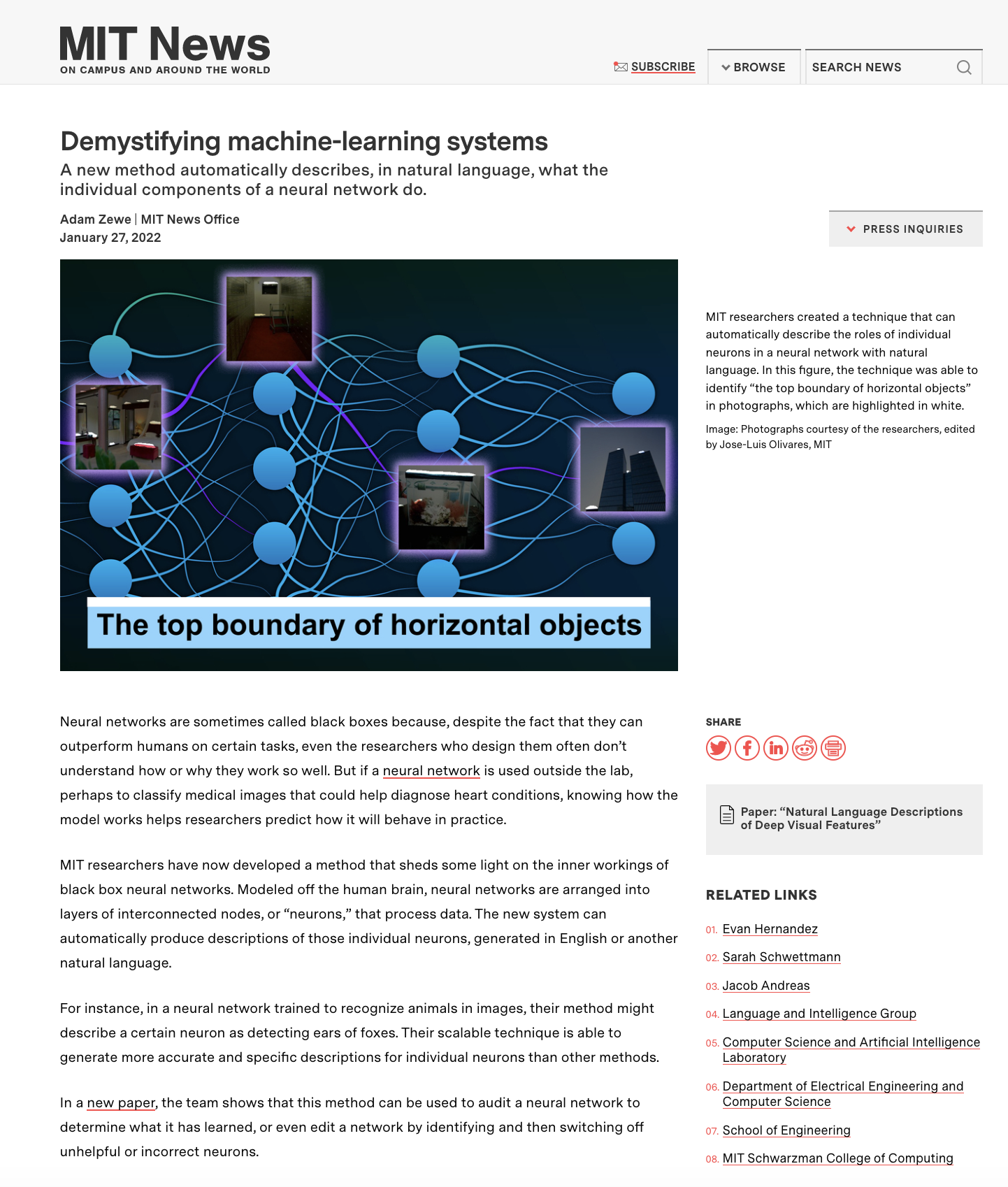
Press
Can We Automatically Describe Neuron Behavior with Natural Language?
Some neurons in deep networks specialize in recognizing highly specific features of inputs. Existing techniques for labeling this behavior are limited in scope. Is a richer characterization of neuron-level computation possible?
Why label neurons with language?
Using natural language to characterize neuron-level computation produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These kinds of rich, open-ended descriptions that make use of the full compositional vocabulary of humans are useful for multiple reasons:
- They surface novel behavior not captured in finite label sets.
- Their richness and detail support applications that help human experts make model-level decisions.
How do we map from neuron activation to description?
Individual units in deep networks can be characterized by the set of inputs that maximally activate them. By visualizing and describing those inputs, we can better understand the role of each neuron in the broader network. Since we are investigating vision models, we use a specific kind of visualization from previous work: the set of top-activating

Another unit in the second convolutional layer of AlexNet responds maximally to horizontal lines on the lower boundary of objects:

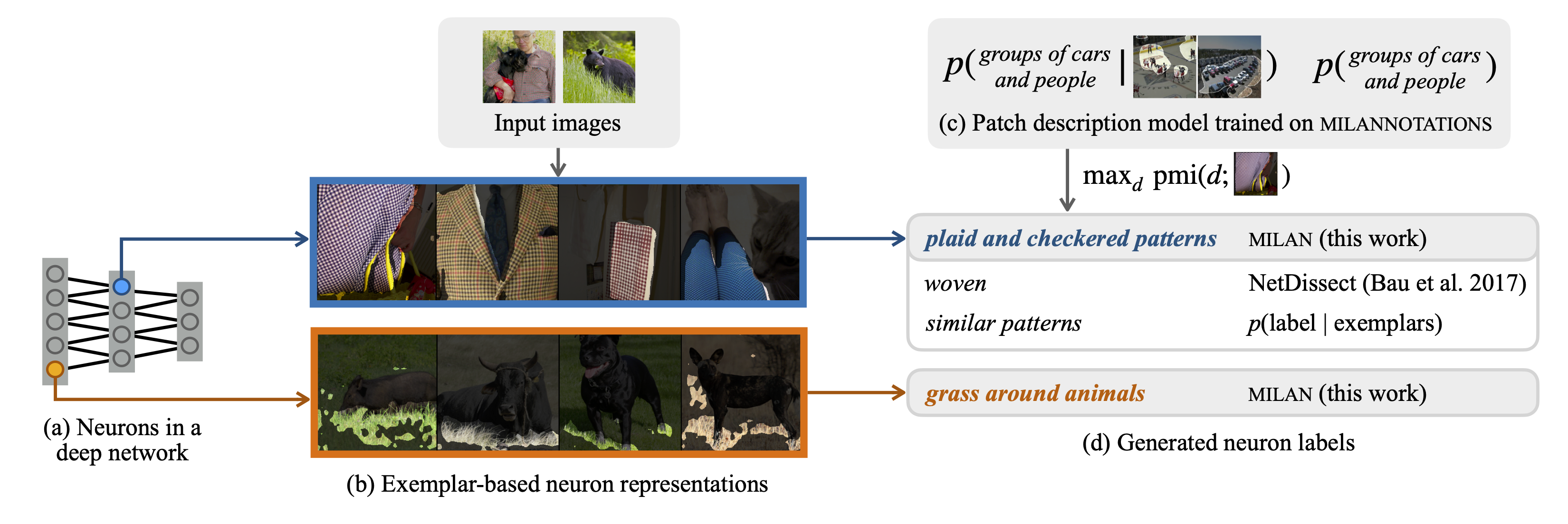
These are the kinds of neuron functionalities we want to describe. To do this, we take the top-activating image regions for a set of neurons, and learn a model (MILAN) that automatically generates natural language descriptions by maximizing the pointwise mutual information between image regions and human annotations of them. To train our model, we gathered a new dataset of image regions paired with language descriptions.
MILANNOTATIONS dataset
We computed the top-activating image regions for 17,000 neurons across 7 models, which themselves span several architectures and tasks. For each set of image regions, we asked three distinct crowd workers to describe what they had in common, resulting in nearly 60,000 descriptions. We are releasing this new dataset with our paper. It can be downloaded from our Github.
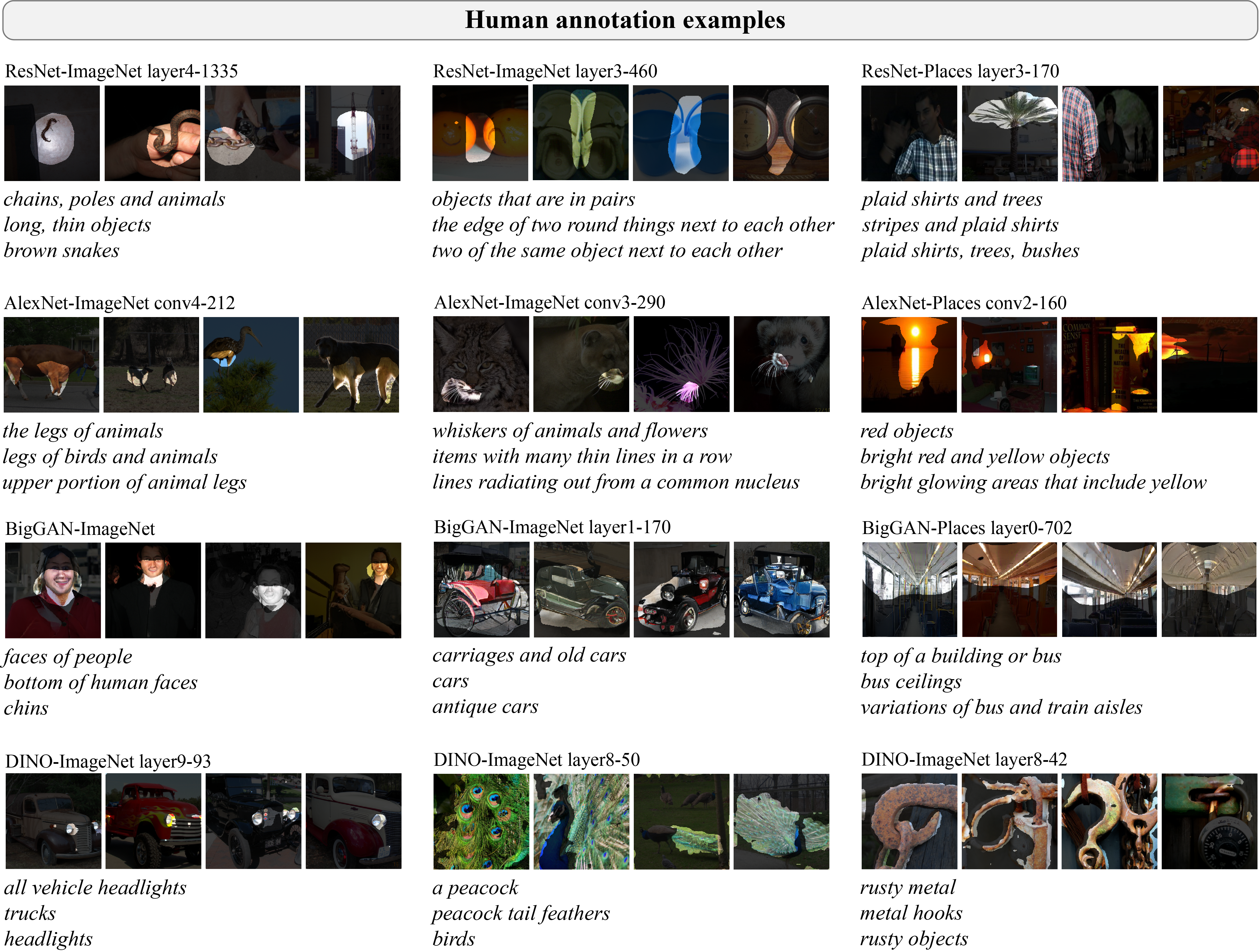
MILAN results
MILAN (Mutual-Information-guided Linguistic Annotation of Neurons) generates descriptions of neurons by maximizing the pointwise mutual information between the description and the image regions that maximally activate that neuron. Implementation details can be found in our paper.
The results below show MILAN's generalization across architecture, dataset, and task. Even highly specific labels (like the top boundaries of horizontal objects) can be predicted for neurons in new networks. Failure modes include semantic errors, e.g. MILAN misses the cupcakes in the dog faces and cupcakes neuron.
How to Cite
bibtex
@InProceedings{hernandez2022natural,
title={Natural Language Descriptions of Deep Visual Features},
author={Hernandez, Evan and Schwettmann, Sarah and Bau, David and Bagashvili, Teona, and Torralba, Antonio and Andreas, Jacob},
booktitle={International Conference on Learning Representations},
year={2022}
url={https://arxiv.org/abs/2201.11114}
}
Acknowledgements We thank Ekin Akyurek and Tianxing He for helpful feedback on early drafts of the paper. We also thank IBM for the donation of the Satori supercomputer that enabled training BigGAN on MIT Places. This work was partially supported by the MIT-IBM Watson AI lab, the SystemsThatLearn initiative at MIT, a Sony Faculty Innovation Award, DARPA SAIL-ON HR0011-20-C-0022, and a hardware gift from NVIDIA under the NVAIL grant program.